Chapitre 2 :INTRODUCTION A LA COMPRESSION:
La compression sans perte :
La compression sans perte signifie que lorsque des données sont compressées et ensuite décompressées, l'information originale contenue dans les données a été préservée. Aucune donnée n'a été perdue ou oubliée. Les données n'ont pas été modifiées.
Les méthodes de compression d’images sans perte sont utiles lorsqu’on veut garder une grande précision, tel que pour des balayages médicaux, ou des numérisations d'images destinées à l'archivage.
Nous allons nous intéresser aux deux algorithmes RLE (basé sur les répétitions) et le codage Huffman (basé sur les statistiques). Ces deux algorithmes sont utilisés lors de la compression JPEG.
RLE (Run Length encoding):
Le run-length encoding, aussi appelé codage par plages, est un algorithme de compression de données en informatique basé sur les répétitions. Ainsi, le RLE s'emploie à réduire la taille physique d'une répétition de chaîne de caractère.
Principe: Compter le nombre d’occurrences d’une chaîne répétée appelée passage (run) à l’aide d’un compteur de passages (run count) et associer ce nombre à chaque séquence, soit à la valeur du caractère répété dans le passage qu’on appelle la valeur de passage (run value). Chacune de ces deux opérations est codée sur un octet, on obtient donc une chaîne de deux octets après codage. Cette représentation est nommée un paquet RLE (RLE packet) dont on génère un nouveau à chaque fois que le caractère change ou chaque fois que le nombre de caractères dans le passage excède la valeur maximum que peut prendre le compteur.
Exemple: « aaaabccdddd aaaabccdddd» cette suite de caractères contient 23 caractères, en suivant la méthode RLE on obtient: 2(4a1b2c4d) qui fait 11 caractères. Cet exemple montre que l’encodage RLE est très efficace si le nombre de redondances est élevé, prenons l’exemple suivant : « abcdefg » 7 caractères RLE >> « 1a1b1c1d1e1f1g » 14 caractères ! La méthode RLE n’est donc pas efficace quand il n’y a pas de redondances !!!
Puisqu’on s’intéresse à la compression d’images numériques, étudions l’application de l’encodage RLE sur un bloc de pixels (Prenons ce bloc de pixels 10x10 ):
![]()
Cette image étant codée sur 24 bits en mode RVB, ce qui donne 1 octet pour chaque couleur élémentaire (1 octet pour le rouge, 1 octet pour le vert et 1 octet pour le bleu).
La taille de cette image sans compression est donc de 3x10x10 = 300 octets. On extrait les matrices de pixels, c'est-à-dire les matrices comportant les valeurs de chaque couleur élémentaire pour chaque pixel :
| 251 | 166 | 214 | 255 | 255 | 255 | 255 | 255 | 251 | 251 |
| 194 | 120 | 129 | 255 | 255 | 255 | 255 | 255 | 255 | 181 |
| 123 | 123 | 208 | 255 | 255 | 255 | 255 | 255 | 255 | 242 |
| 220 | 255 | 255 | 255 | 246 | 209 | 213 | 249 | 255 | 255 |
| 255 | 255 | 255 | 223 | 159 | 143 | 125 | 214 | 250 | 255 |
| 235 | 253 | 255 | 224 | 144 | 218 | 235 | 247 | 255 | 244 |
| 188 | 248 | 247 | 183 | 126 | 242 | 255 | 255 | 255 | 227 |
| 240 | 255 | 252 | 240 | 135 | 236 | 255 | 255 | 255 | 248 |
| 254 | 255 | 244 | 240 | 245 | 251 | 253 | 250 | 255 | 217 |
| 255 | 255 | 147 | 136 | 201 | 183 | 245 | 223 | 202 | 127 |
| 251 | 166 | 214 | 255 | 255 | 255 | 255 | 255 | 251 | 251 |
| 194 | 120 | 129 | 255 | 255 | 255 | 255 | 255 | 255 | 181 |
| 123 | 123 | 208 | 255 | 255 | 255 | 255 | 255 | 255 | 242 |
| 220 | 255 | 255 | 255 | 246 | 209 | 213 | 249 | 255 | 255 |
| 255 | 255 | 255 | 223 | 159 | 143 | 125 | 214 | 250 | 255 |
| 235 | 253 | 255 | 224 | 144 | 218 | 235 | 247 | 255 | 244 |
| 188 | 248 | 247 | 183 | 126 | 242 | 255 | 255 | 255 | 227 |
| 240 | 255 | 252 | 240 | 135 | 236 | 255 | 255 | 255 | 248 |
| 254 | 255 | 244 | 240 | 245 | 251 | 253 | 250 | 255 | 217 |
| 255 | 255 | 147 | 136 | 201 | 183 | 245 | 223 | 202 | 127 |
| 251 | 166 | 214 | 255 | 255 | 255 | 255 | 255 | 251 | 251 |
| 194 | 120 | 129 | 255 | 255 | 255 | 255 | 255 | 255 | 181 |
| 123 | 123 | 208 | 255 | 255 | 255 | 255 | 255 | 255 | 242 |
| 220 | 255 | 255 | 255 | 246 | 209 | 213 | 249 | 255 | 255 |
| 255 | 255 | 255 | 223 | 159 | 143 | 125 | 214 | 250 | 255 |
| 235 | 253 | 255 | 224 | 144 | 218 | 235 | 247 | 255 | 244 |
| 188 | 248 | 247 | 183 | 126 | 242 | 255 | 255 | 255 | 227 |
| 240 | 255 | 252 | 240 | 135 | 236 | 255 | 255 | 255 | 248 |
| 254 | 255 | 244 | 240 | 245 | 251 | 253 | 250 | 255 | 217 |
| 255 | 255 | 147 | 136 | 201 | 183 | 245 | 223 | 202 | 127 |
Ce qui donne :
3x 251 (premier pixel avec R =251 , V=251 , B=251) + 3x166 + 3x214 + 15x255 + 6x251 + 3x194 + 3x120 +3x129 + 18x255 + 3x181 + 6x123 + 3x208 + 6x255 + 3x242 + 3x220 + 9x255 + 3x246 + 3x209 + 3x213 + 3x249 + 15x255 + 3x223 + 3x159 + 3x143 + 3x125 + 3x214 + 3x250 + 3x255 + 3x188 + 3x 248 + 3x247 + 3x183 + 3x126 + 3x242 + 9x255 + 3x248 + 3x254 + 3x255 + 3x244 + 3x240 + 3x245 + 3x251 + 3x250 + 3x255 + 3x217 + 6x255 + 3x147+ 4x136 + 3x201 + 3x183 + 3x245 + 3x223 + 3x202 + 3x127.
Taille de l’image compressée est de 108 octets !!!!
(Le fichier compressé codé en binaire va être de la forme suivante : 00000011 11111011 00000011 10100110 …)
Huffman (Méthode statistique) :
Méthode inventée par D.A. Huffman en 1952. Cet algorithme est capable de faire une analyse statistique de données et ainsi associer aux séquences qui se répètent un code plus court qu’aux séquences plus rares (code à longueur variable).
Cet algorithme utilise un dictionnaire de codes où sont stockées les données issues de l’analyse statistique. Ce dictionnaire doit être conservé entre la compression et la décompression.
Principe : L’algorithme effectue tout d’abord une analyse pour trouver la fréquence (nombre d’occurrences) de chaque séquence (caractère pour un texte, code de couleur pour un pixel,...) dont on reporte le résultat dans une table de fréquence. Ensuite on crée un arbre binaire à partir de ces informations ; chaque séquence constitue une de feuilles de l’arbre à laquelle on associe un poids valant sa fréquence. A chaque deux nœuds de poids faible on associe un père de poids équivalent à la somme des poids de ses fils jusqu’à ce qu’on arrive à la racine. Ensuite le code 0 est associé à la branche droite et le code 1 à la branche gauche ou vice-versa.
Pour obtenir le code binaire il suffit de remonter l’arbre à partir de la racine jusqu’aux feuilles en rajoutant à chaque fois le code adéquat (0 ou 1) selon la branche suivie.
Exemple: Codage de l’expression suivante : « Compression d’une image numérique »
Selon le code ASCII et le codage de Huffman:
- Code ASCII
Code ASCII de chaque caractèreeESPmnuior1100101 0000000 1101101 1101110 1110101 1101001 1101111 1110010 Code ASCII de chaque caractère (suite) sCpdaq'g1110011 1000011 1110000 1100100 1100001 1110001 0100111 1100111 Dans le code ascii chaque caractère est codé sur 7 bits :
Dans la phrase « Compression d’une image numérique » on a 33 caractères, donc 33*7 =231 bits=28 octets. Ce qui donne :
1000011 1101111 1101101 1110000 111010 1100101 1110011 1110011 1101001 1101111 1101110 0000000 1100100 0100111 1110101 1101110 1100101 0000000 1101001 1101101 1100001 1100111 1100101 0000000 1101110 1110101 1101101 1100101 1110010 1101001 1110001 1110101 1100101 -
Le code HUFFMAN
La table des fréquenceseespmnUiorsCpdaq'g5333332221111111
L'arbre de Huffman
L’arbre de Huffman n’est pas unique
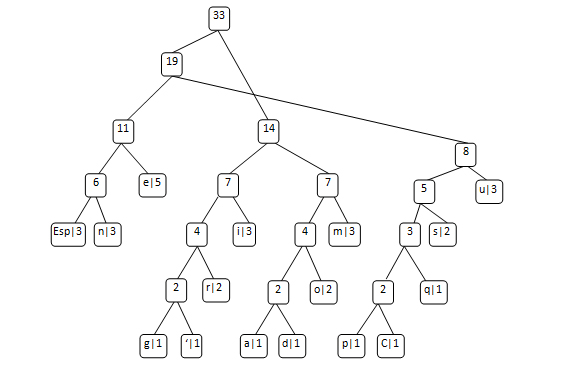
Le code 0 est associé à la branche gauche et le code 1 à la branche droite ou vice-versa
Le code Huffman de chaque caractère eespmnuiorsCpdaq'g001000011100010111011101100101010100010100001100111000010011000110000
Le code Huffman de « Compression d’une image numérique » :
010001 1101 111 010000 1001 001 0101 0101 101 1101 0001 0000 11001 10001 011 0001 001 0000 101 111 11000 10000 001 0000 0001 011 111 001 1001 101 01001 011 001
Soit 123 bits ( 231 avant la compression Huffman).
On peut classifier les méthodes de compressions en deux types : avec perte et sans perte.